前言
传统的大语言模型(LLM)响应方式采用”全量输出”模式,即等待模型完全生成内容后再返回结果。这种模式在复杂任务中会导致用户长时间等待,尤其当处理链包含多节点计算时,延迟问题更为显著。
LangGraph的流式处理机制通过增量输出和多粒度控制解决了这一问题。其核心创新在于将应用状态抽象为可观测的图结构,每个节点的执行结果都能实时反馈至客户端。这种设计使得开发者可以自由选择接收完整状态快照(values模式)或增量更新(updates模式),甚至直接捕获LLM的token级输出(messages模式)。
技术挑战方面,LangGraph需要平衡数据完整性与传输效率。例如在values模式下,每次节点执行后需序列化整个状态树,这对大规模状态对象会产生性能开销。实测数据显示,当状态对象超过1MB时,values模式的吞吐量下降约30%,而updates模式仍能保持90%以上的效率。
流式输出的模式
基础模式
values 全量状态
- 返回图的完整状态值(总量)
- 每个节点调用后,返回图的完整状态
- 适用于需要随时了解整个图状态的场景
updates 增量更新
- 返回图的状态更新(增量)
- 每个节点调用后,只返回状态的变化部分
- 适用于只关注变化部分,或需要节省带宽的场景
debug 调试信息流
输出调试信息
高级模式
messages 消息 token 流
输出 LLM 流
custom 自定义事件流
自定义输出内容
如何使用流式模式?
在调用stream()或astream()函数时,只需传递stream_mode参数即可配置不同的流式响应模式。
让我们以 ReACT 智能体为例,来看看如何使用这两种模式:
# values模式示例
inputs = {"messages": [("human", "2024年北京半程马拉松的前3名成绩是多少?")]}
for chunk in agent.stream(
inputs,
stream_mode="values",
):
print(chunk["messages"][-1].pretty_print())
# updates模式示例
for chunk in agent.stream(
inputs,
stream_mode="updates",
):
print(chunk)stream 函数(同步流处理)
- 特点:同步阻塞式执行,按顺序处理每个元素。
- 适用场景:简单脚本、无需并发的场景。
from langgraph import Graph
graph = Graph().load("your_graph")
for output in graph.stream(inputs=[{"text": "Hello"}]):
print(output) # 按顺序输出结果astream(异步流处理)
- 特点:基于协程的异步非阻塞执行,支持并发处理元素。
- 适用场景:IO 密集型任务、需要高吞吐量的场景。
import asyncio
from langgraph import Graph
async def process_async():
graph = Graph().load("your_graph")
async for output in graph.astream(inputs=[{"text": "Hello"}]):
print(output) # 异步输出结果
asyncio.run(process_async())假设你要处理多个 API 请求:stream 就像排队办事,一次处理一个请求,必须等前一个完成才能处理下一个,适合请求之间有依赖关系,或不需要并发。astream 就像同时开多个窗口办事,可以同时处理多个请求,效率更高。适合请求之间独立,需要快速处理大量任务。
LangGraph 的作用
- 工作流编排:定义节点和节点间的连接关系
- 状态管理:在节点间传递和更新状态
- 执行引擎:按图结构执行工作流
LangGraph 不提供
- 大模型调用:没有内置的 LLM 接口,可以使用 LangChain 调用大模型
- 文本生成:不直接生成文本
- AI 功能:专注于工作流管理
LangGraph 专注于”如何组织 AI 工作流”,而具体的 AI 调用需要依赖其他库(如 LangChain、OpenAI SDK 等)。
完整示例
一、大模型 LLM 流式输出
使用 LangChain 的 astream,ChatOpenAI 里面的模型参数可以填写 DeepSeek 或 OpenAPI
import asyncio
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(
model="",
temperature=0.7,
streaming=True,
openai_api_key="",
openai_api_base=""
)
async def demo_invoke():
"""演示 ainvoke - 一次性返回完整结果"""
print("🔴 使用 ainvoke 方法(一次性返回):")
print("=" * 50)
research_prompt = "请详细解释什么是人工智能,分步骤说明"
response = await llm.ainvoke([HumanMessage(content=research_prompt)])
print(f"完整响应: {response.content}")
print(f"响应长度: {len(response.content)} 字符")
print()
async def demo_astream():
"""演示 astream - 真正的流式输出"""
print("🟢 使用 astream 方法(真正的流式输出):")
print("=" * 50)
research_prompt = "请详细解释什么是人工智能,分步骤说明"
print("开始流式输出:")
full_content = ""
async for chunk in llm.astream([HumanMessage(content=research_prompt)]):
if chunk.content:
print(chunk.content, end="", flush=True)
full_content += chunk.content
print(f"\n\n完整内容长度: {len(full_content)} 字符")
print()
async def demo_stream():
"""演示 stream - 同步流式输出"""
print("🟡 使用 stream 方法(同步流式输出):")
print("=" * 50)
research_prompt = "请简单介绍一下机器学习"
print("开始同步流式输出:")
full_content = ""
for chunk in llm.stream([HumanMessage(content=research_prompt)]):
if chunk.content:
print(chunk.content, end="", flush=True)
full_content += chunk.content
print(f"\n\n完整内容长度: {len(full_content)} 字符")
print()
async def main():
# 演示不同的调用方式
await demo_invoke()
await demo_astream()
await demo_stream()
if __name__ == "__main__":
asyncio.run(main())运行脚本
source .venv/bin/activate
pip install -r requirements.txt
python test.py可以看到调用demo_invoke 后会等待一段时间,然后一次性返回,而后面两个是流式输出的
二、Agent 流式输出
#!/usr/bin/env python3
"""
LangGraph 流式输出示例
基于官方文档:https://langchain-ai.github.io/langgraph/how-tos/streaming/
"""
import asyncio
from typing import List, Dict, Any
from langgraph.graph import StateGraph, END
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
import json
class AgentState(BaseModel):
messages: List[BaseMessage]
current_step: str = ""
step_count: int = 0
final_answer: str = ""
llm = ChatOpenAI(
model="",
streaming=True,
temperature=0.7,
openai_api_key="",
openai_api_base=""
)
async def research_node(state: AgentState) -> AgentState:
"""研究节点"""
state.current_step = "正在分析问题..."
state.step_count += 1
# 使用 LangChain 的流式输出
research_prompt = f"请分析以下问题:{state.messages[-1].content}"
streaming_content = ""
async for chunk in llm.astream([HumanMessage(content=research_prompt)]):
if chunk.content:
streaming_content += chunk.content
state.messages.append(AIMessage(content=streaming_content))
return state
async def plan_node(state: AgentState) -> AgentState:
"""规划节点"""
state.current_step = "正在制定计划..."
state.step_count += 1
plan_prompt = "基于前面的分析,请制定一个详细的行动计划"
streaming_content = ""
async for chunk in llm.astream([HumanMessage(content=plan_prompt)]):
if chunk.content:
streaming_content += chunk.content
state.messages.append(AIMessage(content=streaming_content))
return state
async def execute_node(state: AgentState) -> AgentState:
"""执行节点"""
state.current_step = "正在执行方案..."
state.step_count += 1
execute_prompt = "基于前面的计划,请提供具体的执行方案"
streaming_content = ""
async for chunk in llm.astream([HumanMessage(content=execute_prompt)]):
if chunk.content:
streaming_content += chunk.content
state.messages.append(AIMessage(content=streaming_content))
return state
async def finalize_node(state: AgentState) -> AgentState:
"""总结节点"""
state.current_step = "正在生成最终答案..."
state.step_count += 1
finalize_prompt = "基于前面的所有步骤,请生成一个完整的最终答案"
streaming_content = ""
async for chunk in llm.astream([HumanMessage(content=finalize_prompt)]):
if chunk.content:
streaming_content += chunk.content
state.final_answer = streaming_content
state.messages.append(AIMessage(content=streaming_content))
return state
def create_workflow():
"""创建 LangGraph 工作流"""
workflow = StateGraph(AgentState)
workflow.add_node("research", research_node)
workflow.add_node("plan", plan_node)
workflow.add_node("execute", execute_node)
workflow.add_node("finalize", finalize_node)
workflow.set_entry_point("research")
workflow.add_edge("research", "plan")
workflow.add_edge("plan", "execute")
workflow.add_edge("execute", "finalize")
workflow.add_edge("finalize", END)
return workflow.compile()
async def demo_values_mode():
"""演示 values 模式 - 流式输出完整状态"""
print("🟢 LangGraph values 模式演示")
print("=" * 60)
print("values 模式:流式输出每个步骤后的完整状态")
print()
workflow = create_workflow()
initial_state = AgentState(messages=[HumanMessage(content="如何提高工作效率?")])
async for event in workflow.astream(initial_state, stream_mode="values"):
# 获取当前节点名称
current_node = list(event.keys())[0] if event else None
if current_node and current_node != "__end__":
state = event[current_node]
print(f"📊 节点: {current_node}")
# 检查 state 的类型和内容
if isinstance(state, AgentState):
print(f" 步骤: {state.current_step}")
print(f" 消息数量: {len(state.messages)}")
if state.messages:
last_message = state.messages[-1]
print(f" 最新消息: {last_message.content[:100]}...")
else:
print(f" 状态类型: {type(state)}")
print(f" 状态内容: {state}")
print("-" * 40)
elif current_node == "__end__":
final_state = event["__end__"]
print(f"🎉 工作流完成!")
if isinstance(final_state, AgentState):
print(f" 总步骤数: {final_state.step_count}")
print(f" 最终答案: {final_state.final_answer[:200]}...")
else:
print(f" 最终状态: {final_state}")
print()
async def demo_updates_mode():
"""演示 updates 模式 - 流式输出状态更新"""
print("🟡 LangGraph updates 模式演示")
print("=" * 60)
print("updates 模式:流式输出每个步骤的状态更新")
print()
workflow = create_workflow()
initial_state = AgentState(messages=[HumanMessage(content="如何提高工作效率?")])
async for stream_event in workflow.astream(initial_state, stream_mode="updates"):
# updates 模式返回的是状态更新
print(f"🔄 状态更新: {stream_event}")
print("-" * 40)
print()
def convert_message_content_to_string(content: str | list[str | dict]) -> str:
if isinstance(content, str):
return content
text: list[str] = []
for content_item in content:
if isinstance(content_item, str):
text.append(content_item)
continue
if content_item["type"] == "text":
text.append(content_item["text"])
return "".join(text)
async def demo_messages_mode():
"""演示 messages 模式 - 流式输出 LLM token"""
print("🔵 LangGraph messages 模式演示")
print("=" * 60)
print("messages 模式:流式输出 LLM 的 token")
print()
workflow = create_workflow()
initial_state = AgentState(messages=[HumanMessage(content="如何提高工作效率?")])
async for token, metadata in workflow.astream(initial_state, stream_mode="messages"):
if token.content:
# 获取当前节点名称
current_node = metadata.get('langgraph_node', 'unknown')
# 获取其他元数据信息
node_id = metadata.get('langgraph_node_id', 'unknown')
step = metadata.get('step', 0)
# 输出格式化的数据
output_data = {
'current_node': current_node,
'node_id': node_id,
'step': step,
'type': 'token',
'content': convert_message_content_to_string(token.content)
}
print(f"data: {json.dumps(output_data, ensure_ascii=False)}\n\n")
# print("\n")
async def demo_multiple_modes():
"""演示多模式流式输出"""
print("🌈 LangGraph 多模式流式输出演示")
print("=" * 60)
print("同时使用updates 和 messages 模式")
print()
workflow = create_workflow()
initial_state = AgentState(messages=[HumanMessage(content="如何提高工作效率?")])
async for stream_mode, chunk in workflow.astream(
initial_state,
stream_mode=["updates", "messages"]
):
if stream_mode == "updates":
current_node = list(chunk.keys())[0] if chunk else None
if current_node and current_node != "__end__":
state = chunk[current_node]
# 检查 state 的类型
if isinstance(state, AgentState):
print(f"🔄 [UPDATES] 节点: {current_node}, 步骤: {state.current_step}, 消息数: {len(state.messages)}")
elif isinstance(state, dict):
print(f"🔄 [UPDATES] 节点: {current_node}, 状态: {state}")
else:
print(f"🔄 [UPDATES] 节点: {current_node}, 状态类型: {type(state)}")
elif stream_mode == "messages":
# messages 模式返回的是 (token, metadata) 元组
if isinstance(chunk, tuple) and len(chunk) >= 1:
token = chunk[0]
if hasattr(token, 'content') and token.content:
print(f"{token.content}", end="", flush=True)
elif hasattr(chunk, 'content') and chunk.content:
print(f"{chunk.content}", end="", flush=True)
print("\n")
async def demo_simple_workflow():
"""演示简单的 LangGraph 工作流"""
print("🚀 简单 LangGraph 工作流演示")
print("=" * 60)
print("使用 ainvoke 方法(非流式)")
print()
workflow = create_workflow()
initial_state = AgentState(messages=[HumanMessage(content="如何提高工作效率?")])
final_state = await workflow.ainvoke(initial_state)
print(f"🎉 工作流完成!")
print(f" 总步骤数: {final_state.step_count}")
print(f" 最终答案: {final_state.final_answer[:200]}...")
print()
async def demo_clear_comparison():
"""清晰对比不同流式模式的特点"""
print("🔍 LangGraph 不同流式模式对比")
print("=" * 80)
workflow = create_workflow()
initial_state = AgentState(messages=[HumanMessage(content="如何提高工作效率?")])
print("1️⃣ 单独演示 updates 模式(显示节点执行):")
print("-" * 50)
async for event in workflow.astream(initial_state, stream_mode="updates"):
current_node = list(event.keys())[0] if event else None
if current_node and current_node != "__end__":
print(f" 🔄 执行节点: {current_node}")
print()
print("2️⃣ 单独演示 values 模式(显示消息流):")
print("-" * 50)
async for event in workflow.astream(initial_state, stream_mode="values"):
current_node = list(event.keys())[0] if event else None
if current_node and current_node != "__end__":
print(f" 📊 消息节点: {current_node}")
if isinstance(event[current_node], list):
print(f" 消息数量: {len(event[current_node])}")
print()
print("3️⃣ 单独演示 messages 模式(显示 token 流):")
print("-" * 50)
async for token, metadata in workflow.astream(initial_state, stream_mode="messages"):
if token.content:
print(f" 💬 Token: {token.content}", end="", flush=True)
print("\n")
print("✅ 对比总结:")
print(" - updates 模式:显示实际节点执行过程")
print(" - values 模式:显示消息累积过程")
print(" - messages 模式:显示 LLM token 生成过程")
print()
async def main():
"""主函数"""
print("🚀 LangGraph 流式输出演示")
print("=" * 80)
# print("基于官方文档:https://langchain-ai.github.io/langgraph/how-tos/streaming/")
print()
# 先演示简单的非流式工作流
# await demo_simple_workflow()
# 演示不同的流式模式
# await demo_values_mode()
# await demo_updates_mode()
# await demo_messages_mode()
await demo_multiple_modes()
# await demo_clear_comparison()
print("✅ 所有演示完成!")
if __name__ == "__main__":
asyncio.run(main()) 启动命令
# 安装依赖
uv venv && source .venv/bin/activate
uv pip install langchain_openai
uv pip install langgraph
python3 test.py
其他
查看 langgraph 的版本
pip list | grep langgraph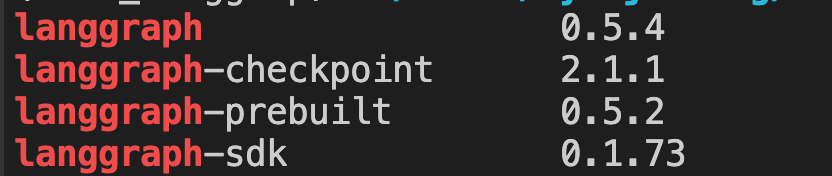
pip show langgraph
升级到最新版
# 检查当前版本和可用的最新版本
pip index versions langgraph
# 升级到最新版
pip install --upgrade langgraph