网站建好了,如何才能让搜索引擎收录网站?如果页面无法被搜索引擎收录,就意味着没有展示,也就无法竞争排名获取 SEO 流量了。
本文将围绕抓取和收录亮点,从基本原理,常见问题和解决方法三个维度探讨搜索引擎优化。
- 什么是抓取、收录
- 网页抓取工具
- robots.txt 文件介绍
- 如何查看网站的收录情况
- 设置网页不被搜索引擎索引
搜索引擎的原理:搜索引擎是把互联网上的网页内容存在自己的服务器上,当用户搜索某个词的时候,搜索引擎就会在自己的服务器上找相关的内容,也就是说,只有保存在搜索引擎服务器上的网页才会被搜索到。
哪些网页才能被保存到搜索引擎的服务器上呢?
只有被搜索引擎的抓取程序抓到的网页才会保存到搜索引擎的服务器上,这个网页抓取程序就是搜索引擎的蜘蛛.整个过程分为爬行和抓取。
一、什么是抓取、收录
抓取(Crawl):
就是搜索引擎爬虫爬取网站的这个过程。Google的官方解释是——“抓取”是指找出新网页或更新后的网页以将其添加到 Google 中的过程;(点击此处查看谷歌官网文档)
收录(Index):
就是搜索引擎把页面存储到其数据库的结果,也叫索引。Google的官方解释是:Google 抓取工具(“Googlebot”)已访问该网页、已分析其内容和含义并已将其存储在 Google 索引中。已编入索引的网页可以显示在 Google 搜索结果中;(点击此处查看谷歌官网文档)
抓取配额(Crawl Budget):
是搜索引擎蜘蛛花在一个网站上的抓取页面的总时间上限。一般小型网站(几百上千个页面)其实并不需要担心,搜索引擎分配的抓取配额够不够;大型网站(百万级或千万级页面)会考虑这个问题更多一些。假如搜索引擎每天抓取的页面数几万个,那整个网站的页面抓取可能就得数月或一年。一般这个数据可以通过Google Search Console后台了解到,如下截图所示,红框中的平均值即网站分配所得的抓取配额。
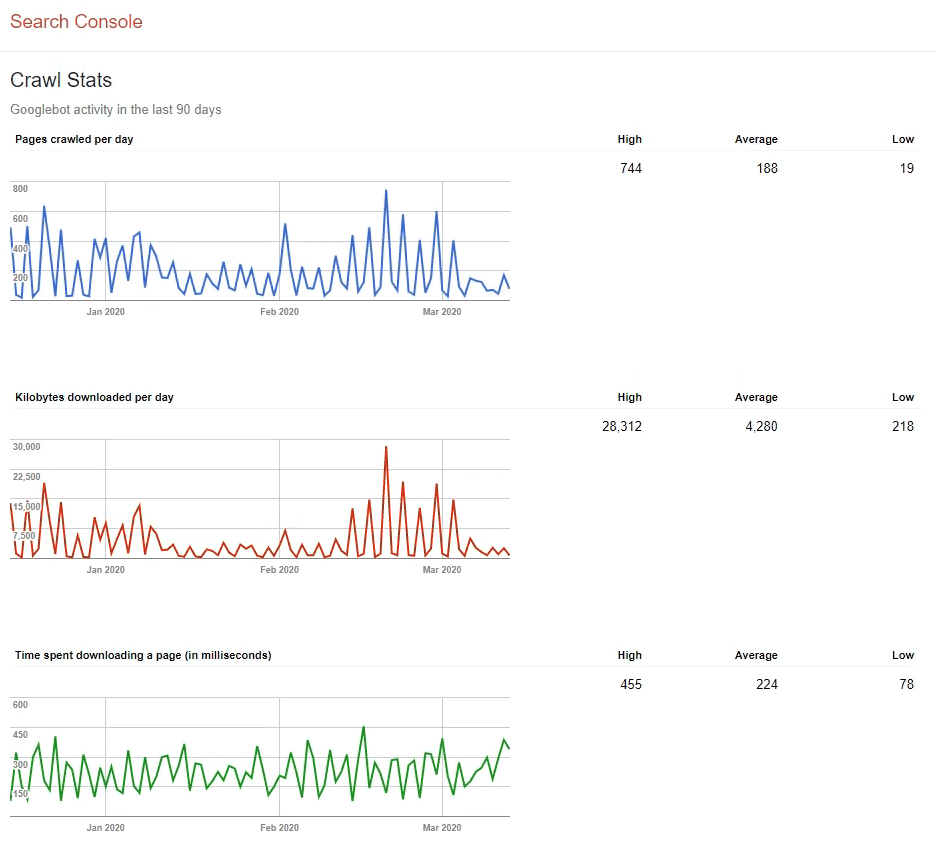
通过一个例子来让大家更好地理解抓取,收录及抓取配额:
把搜索引擎比喻为一座庞大的图书馆,把网站比喻为一间书店,书店中的书本比喻为网站页面,蜘蛛爬虫比喻为图书馆采购员。
采购员为了丰富图书馆的藏书,会定期到书店查看是否有新的书本进货,翻阅书本的这个过程就可以理解为抓取;
当采购员觉得这本书有价值,就会购买带回图书馆进行收藏,这个书本收藏就是我们所说的收录;
每个采购员的购书预算是有限的,他会优先购买价值高的书本,这个预算就是我们理解的抓取配额。
二、网页抓取工具
“抓取工具”是一个统称,泛指通过跟踪从一个网页指向另一个网页的链接自动发现并扫描网站的任何程序(如漫游器或“蜘蛛”程序)。Google 的主要抓取工具叫作 Googlebot。
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
三、robots.txt 文件介绍
robots.txt 文件中规定某个抓取工具的抓取规则。
robots.txt 文件必须位于主机的顶级目录中。
一般情况下,robots.txt 文件会出现三种不同的抓取结果:
- 全部允许:所有内容均可抓取。
- 全部禁止:所有内容均不能抓取。
- 有条件地允许:robots.txt 中的指令决定是否可以抓取某些内容。
robots.txt 用法举例:
网站目录下所有文件均能被所有搜索引擎蜘蛛访问
User-agent: *
Disallow:
禁止所有搜索引擎蜘蛛访问网站的任何部分
User-agent: *
Disallow: /
禁止所有的搜索引擎蜘蛛访问网站的几个目录
User-agent: *
Disallow: /a/
Disallow: /b/
只允许某个搜索引擎蜘蛛访问
User-agent: Googlebot
Disallow:
屏蔽所有带参数的 URL
User-agent: *
Disallow: /*?
应该限制网站某些文件不被蜘蛛抓取:
一般网站中不需要蜘蛛抓取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等等。
robots.txt文件带来的风险以及解决:
robots.txt 同时也带来了一定的风险:其也给攻击者指明了网站的目录结构和私密数据所在的位置。设置访问权限,对您的隐私内容实施密码保护,这样,攻击者便无从进入。
四、如何查看网站的收录情况
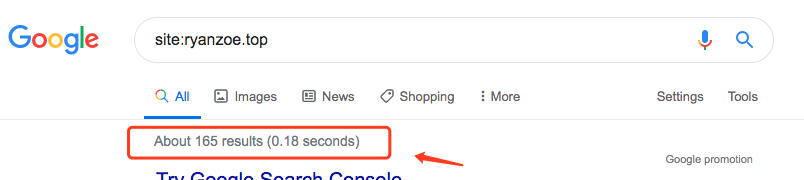
①通过Site命令。
主流的搜索引擎如Google,Baidu及Bing都是支持Site命令的。通过Site命令可以在宏观层面查看一个网站被收录了多少页面,这个数值是不精确的,有一定的波动性,但是具有一定的参考价值。如下图所示,ryanzoe.top 网站被 Google 收录的网页数大概为 165 个
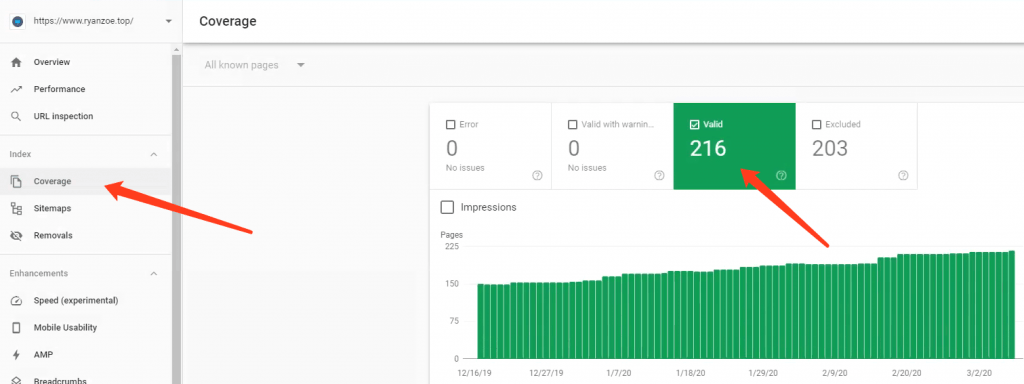
②如果网站已经验证了Google Search Console,这就可以获取网站被Google收录的精确数值,如下图红框所示,Google收录了ryanzoe.top 网站的 216 个页面
③如果想查询特定的页面是否被收录,可以通过info命令,Google是支持info命令的,百度和Bing不支持,在google中输入 info:URL , 如果有结果返回,即页面已经被收录,如下图所示:
五、设置网页不被搜索引擎索引
建议使用 robots meta 标签,在 head 标签中添加如下代码:
<meta name="robots" content="noindex, nofollow">可以将多个指令 合并为一个以英文逗号分隔的列表,这些指令不区分大小写。
all
对索引编制或内容显示无任何限制。该指令为默认值,因此明确列出时并无任何效果。
noindex
不在搜索结果中显示此网页。nofollow不追踪该网页上的链接。
none
等同于 noindex, nofollow。noarchive不在搜索结果中显示缓存链接。
nosnippet
不在搜索结果中显示该网页的文本摘要或视频预览。静态图片缩略图(如果有)若能够实现更好的用户体验,就可能仍会显示。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 探索)。
max-snippet:[number]
最多只能使用 [number] 个字符作为此搜索结果的文字摘要。(请注意,网址可能会在搜索结果页中显示为多个搜索结果。)这并不会影响图片或视频预览。这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 探索、Google 助理)。但是,如果发布商已单独授予内容使用权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容或与 Google 签订了许可协议,则此设置不会妨碍这些更具体的允许用途。如果未指定可解析的 [number],此指令会被忽略。
特殊值:
0:不会显示任何摘要。等同于nosnippet。-1:没有摘要长度限制。
示例:
<meta name="robots" content="max-snippet:20">max-image-preview:[setting]
设置此网页的图片预览在搜索结果中的尺寸上限。
接受的 setting 值:
none:不会显示图片预览。standard:可能会显示默认图片预览。large:可能会显示较大的图片预览,最高达到视口宽度。
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 探索、Google 助理)。但是,如果发布商已单独授予内容使用权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 网页和规范版本的文章),或与 Google 签订了许可协议,则此设置不会妨碍这些更具体的允许用途。
如果发布商不希望 Google 将其 AMP 网页和规范版本的文章显示在搜索结果页或“探索”功能中时使用较大的缩略图,则应将 max-image-preview 的值指定为 standard 或 none。
示例:
<meta name="robots" content="max-image-preview:standard">max-video-preview:[number]
此网页上的视频在搜索结果中的视频摘要时长不得超过 [number] 秒。
其他支持的值:
0:根据 max-image-preview 设置,最多只能使用静态图片。-1:没有限制。
这适用于所有形式的搜索结果(例如 Google 网页搜索、Google 图片、Google 视频、Google 探索、Google 助理)。如果未指定可解析的 [number],此指令会被忽略。
示例:
<meta name="robots" content="max-video-preview:-1">notranslate
不在搜索结果中提供该网页的译文。
noimageindex
不将该网页上的图片编入索引。
unavailable_after: [date/time]
在指定日期/时间过后,不在搜索结果中显示该网页。日期/时间必须以广泛采用的格式指定,包括但不限于 RFC 822、RFC 850 和 ISO 8601。如果未指定有效的 [date/time],此指令会被忽略。默认情况下,内容没有失效日期。
示例:
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-24 01:00:00 PDT">参考资料:
https://developers.google.com/search/reference/robots_meta_tag