RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了“检索”与“生成”两种能力的人工智能技术,常用于智能问答、知识问答、企业知识库等场景。
RAG的核心思想
传统的大语言模型(如GPT)只能基于训练时学到的知识来回答问题,无法利用最新的、外部的、动态变化的信息。而RAG通过引入“检索”机制,让模型在生成答案前,先从外部知识库中检索相关信息,再结合这些信息生成更准确、更有依据的回答。
在 RAG 中,“召回”指的是从外部知识库或文档库中检索出与用户问题相关的信息片段的过程。这个过程通常发生在生成模型(如GPT)生成最终答案之前。
具体来说,RAG 流程分为两步:
检索(Retrieval)
首先,系统会根据用户的输入(问题、查询等),在一个预先构建好的知识库、文档库或向量数据库中,检索出若干条最相关的内容(比如文本片段、文档、FAQ等)。这个过程就叫“召回”。常用的召回方式有基于向量相似度的检索(如FAISS、Milvus等),也有基于关键词的检索(如Elasticsearch)。
生成(Generation)
然后,生成模型会结合用户输入和召回到的内容,生成最终的回答。
举例说明:假如你问“RAG里面的召回是什么意思?”,RAG系统会先在知识库里检索(召回)出几段和“RAG”“召回”相关的内容,然后再用大模型把这些内容和你的问题结合起来,生成一段解释。总结:RAG里的“召回”就是“检索相关信息”的意思,是RAG流程中非常关键的第一步。
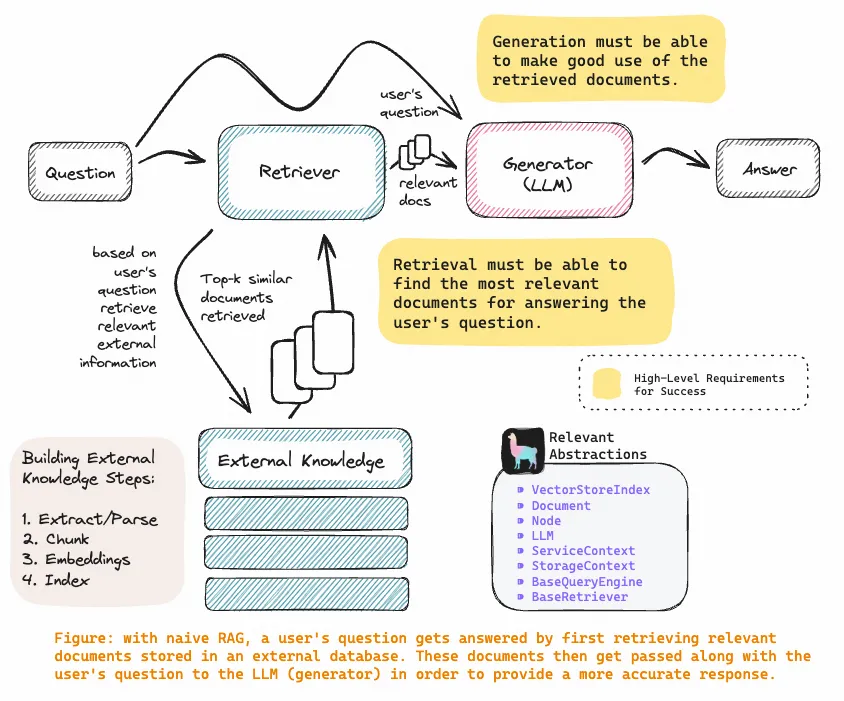
上图为 RAG 应用的通用范式,也是目前通用的知识库问答方案,可以简单总结为下面的流程
用户问题 → 搜索文档 → 封装 prompt → 模型回答
RAG的优点
- 能利用最新的、外部的知识,突破大模型知识“过时”的限制。
- 回答更有依据,可以溯源到原始文档。
- 支持企业/个人定制知识库,适应性强。
应用场景
- 企业智能客服
- 法律、医疗等专业领域的知识问答
- 内部文档搜索与问答
- 智能助手
总结
RAG 就是“先查资料,再作答”,让AI既有“查找资料”的能力,又有“组织语言”的能力。
目前效果比较好的方案:自适应 RAG,通过查询类型,自动选择最合适的检索策略,这种方案,结合了多种检索方式,提高了知识库的精度。