前言
要了解字符编码,首先得先知道为什么字符需要编码?由于计算机只能识别 01 这种二进制数据,所以如果我们将一段文字存储到电脑里,就得将我们的文本编码为计算机能读懂二进制。所以字符编码是将字符集(如字母、数字和符号)映射到计算机可以理解和存储的数字代码的过程。由于计算机最先是美国人发明的,所以一开始只兼容了 ASCII 编码,也就是大小写字母以及一些特殊符号,一共 128 个。
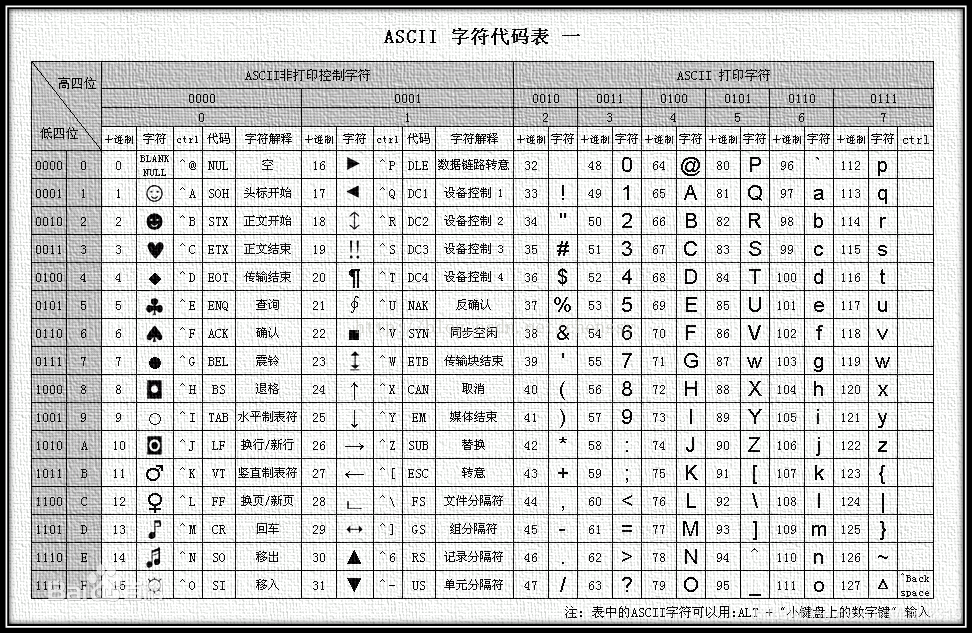
ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种字符编码标准,用于表示文本在计算机、通信设备以及其他依赖文本的设备中的字符。ASCII 最初于 1963 年发布,后来在 1986 年进行了最后的更新,它基于拉丁字母,并为每个字符分配了一个从 0 到 127 的数字代码。
占用空间
ASCII 编码的字符占用一个字节,一个字节等于 8 位,由于 2 的 7 次方等于 128,所以 ASCII 实际上还保留了一位,最多可以有 256 个字符。
ASCII 编码包括以下几类字符:
- 控制字符(0-31 & 127):这些字符没有对应的打印形式,它们用于控制像打印机这样的设备,或者用于文本流的控制。例如,换行(LF)是 ASCII 10,回车(CR)是 ASCII 13。
- 可打印字符(32-126):这些字符包括英文大写和小写字母、数字、标点符号以及一些特殊符号。例如,大写字母 A 的 ASCII 是 65,小写字母 a 的 ASCII 是 97,数字 0 的 ASCII 是 48。
ASCII 是计算机科学和通信领域的基础,尽管它只能表示有限的字符集,但它在早期计算机技术中发挥了重要作用。随着计算机技术的发展,为了支持更多语言和符号,出现了扩展 ASCII 和其他编码标准,如 ISO 8859-1 和 Unicode。Unicode 是目前最广泛使用的编码标准,它包含了 ASCII 作为其子集,并扩展了字符集以包括全球各种语言和符号。
GBK
GBK 是一种在简体中文环境中广泛使用的字符编码标准。GBK 全称是《汉字内码扩展规范》(GBK即“国标”、“扩展”的汉语拼音首字母),它是对 GB2312 编码的扩展,由中国国家技术监督局于 1995 年发布。GBK 编码能够覆盖简体中文所需的几乎所有字符,并且包含了一些繁体中文字符以及日文假名等。
GBK 编码的特点包括:
- 向后兼容 GB2312:GBK 编码包含了 GB2312 的所有字符,并在此基础上进行了扩展。这意味着任何 GB2312 编码的文本在 GBK 编码下都是有效的。
- 包含更多字符:GBK 编码扩展了字符集,包括了更多的汉字和符号,总共包含了 21000 多个字符。
- 双字节编码:GBK 是一种变长编码,它使用 1 到 2 个字节来表示一个字符。ASCII 字符仍然使用单字节表示,而中文字符则使用双字节表示。
- 广泛应用:GBK 编码在中国大陆的 Windows 操作系统和其他软件中得到了广泛应用,尤其是在 Unicode 成为主流之前。
尽管 Unicode 编码(特别是 UTF-8)现在已经成为国际标准,并且在新的系统和应用程序中得到了广泛采用,GBK 编码仍然在一些旧的系统和应用程序中使用,特别是在一些需要与旧数据或旧软件兼容的场景中。随着时间的推移,GBK 编码逐渐被 Unicode 取代,因为 Unicode 提供了更全面的字符集支持和更好的国际化能力。
占用空间
中文字符占用 2 个字节,英文占用 1 个字节
Unicode
Unicode 是一个国际标准,旨在为世界上所有的书写系统提供一个唯一的数字标识(称为代码点)。Unicode 能够表示超过 140,000 个字符,包括字母、标点符号、数字、符号、表情符号、历史文本、全球各种语言的字符,甚至还包括音乐和数学符号。
Unicode 的主要目标是解决传统字符编码方案的局限性和不一致性问题。在 Unicode 出现之前,存在许多不同的编码系统,如 ASCII、ISO 8859-1 等,它们通常只能表示少量字符,而且彼此不兼容,这导致了跨语言和国际化应用程序的开发困难。
Unicode 提供了几种不同的编码形式(UTF-8、UTF-16、UTF-32)
UTF-8:是一种变长的编码方式,使用 1 到 4 个字节来表示每个 Unicode 字符。中文字符占用 2 个字节,英文占用 1 个字节。UTF-8 的一个重要特性是它向后兼容 ASCII,即 ASCII 编码的文本在 UTF-8 编码中保持不变。这使得 UTF-8 成为互联网上最流行的 Unicode 编码。
UTF-16:使用 2 个或 4 个字节来表示每个 Unicode 字符。对于 Unicode 范围内的基本多文种平面(BMP)中的字符,UTF-16 使用 2 个字节编码,而对于辅助平面的字符,使用一对 2 个字节(称为代理对)。
UTF-32:使用固定的 4 个字节来表示每个 Unicode 字符。这种编码方式简单直接,但不如 UTF-8 或 UTF-16 空间效率高。
Unicode 的出现极大地简化了全球化软件的开发,使得软件能够以统一的方式处理多种语言的文本,而不必担心字符编码的问题。它现在被操作系统、编程语言、数据库和网络协议广泛支持,并且是现代软件国际化和本地化的基石。
Base64
Base64 是一种基于 64 个可打印字符(这个字符集包括大写字母 A-Z、小写字母 a-z、数字 0-9、加号 (+) 和斜杠 (/))来表示二进制数据的编码方法。它的设计目的是使二进制数据在不同的系统之间通过文本媒介(如电子邮件或数据存储)安全地传输或存储。Base64 编码后的数据由一组 ASCII 字符组成,这些字符在大多数字符编码中都是相同的,因此可以安全地传输或存储。
Base64 编码原理
以下是 Base64 编码的详细步骤:
- 二进制数据分组:将原始数据的二进制串按照 8 位一组(即一个字节)分组。如果最后一组不足 8 位,会添加零位(padding)使其达到 8 位。
- 重新分组:将这些 8 位一组的数据重新分成 6 位一组的数据块。这意味着每个字节会被拆分,可能跨越到相邻的数据块中。如果最后一组不足 6 位,同样会添加零位使其达到 6 位。
- 映射到 Base64 字符集:每个 6 位的数据块现在表示一个 0 到 63 之间的数值。将这个数值映射到 Base64 字符集中对应的字符。
- 输出编码字符串:将所有映射得到的字符连接起来,形成一个 Base64 编码的字符串。
- 添加填充字符:Base64 编码要求输出的字符数必须是 4 的倍数。如果最后一个 4 字符组不足 4 个字符,会添加等号 (=) 作为填充字符。最多会添加两个等号,因为 6 位的数据块最多只会缺少 4 位或 2 位。
例如,假设我们有三个 ASCII 字符 “Man”,它们的二进制表示如下:
- M: 77 -> 01001101
- a: 97 -> 01100001
- n: 110 -> 01101110
将这些二进制数据串联起来得到:
01001101 01100001 01101110
然后,将这个 24 位的二进制数分成四组 6 位的数据块:
010011 010110 000101 101110
这些 6 位的数据块对应的十进制数值分别是:
19 22 5 46
根据 Base64 字符集,这些数值对应的字符是:
T W F u
因此,”Man” 的 Base64 编码是 “TWFu”。
Base64 的作用以及应用场景
Base64 的作用:
- 使二进制数据可读:Base64 编码将二进制数据转换为文本格式,使其可以通过文本传输协议(如 HTTP 或 SMTP)发送。
- 数据完整性:Base64 编码保持了原始二进制数据的完整性,因为它是一种无损编码方式。
- 避免特殊字符问题:在某些系统中,如 URL、XML 或某些文件系统中,特殊字符可能会引起问题。Base64 编码后的数据不包含这些特殊字符,因此可以避免这些问题。
应用场景:
- 电子邮件:电子邮件标准(如 MIME)使用 Base64 编码来传输非文本附件(如图片、音频、视频或其他二进制文件)。
- 数据 URL:在 HTML 或 CSS 中,Base64 编码用于创建内联图像(data URLs),这样可以将图像数据直接嵌入到 HTML 或 CSS 文件中,而不是通过外部文件引用。
- WebSockets 和其他二进制通信:在 WebSockets 等二进制通信协议中,Base64 编码用于在客户端和服务器之间传输二进制数据。
- 基本身份验证:在 HTTP 基本身份验证中,用户名和密码组合经常使用 Base64 编码后发送到服务器。
- 令牌和 API 密钥:在某些安全令牌(如 JWT)和 API 密钥中,Base64 编码用于表示复杂的二进制数据。
- 存储和传输加密数据:Base64 编码用于存储和传输加密数据,因为加密后的数据通常是二进制的。
Base64 编码不是一种加密方法,它不提供任何安全性或隐私保护。Base64 编码后的数据可以轻松解码回原始二进制形式。因此,如果数据需要安全保护,应该在 Base64 编码之前对其进行加密处理。